문제풀이 - 925. Long Pressed Name
- 문제
- 1. 접근
- 2. 제출한 답
- 3. 코드에 대한 반성
- 4. 문자열 리터럴 비교와 변수에 저장된 문자열의 비교
- 5. 문자열 인터닝(String Interning)
- 6. 더 나은 코드
- 7. 추가 공부
문제
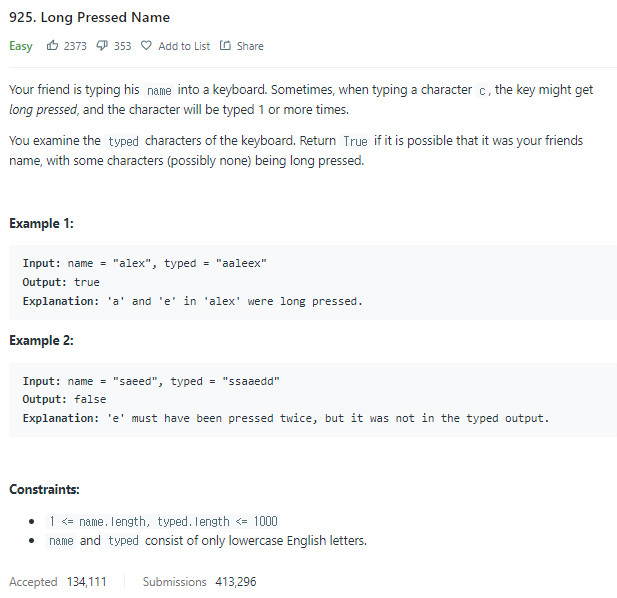
https://leetcode.com/problems/long-pressed-name/
1. 접근
시행착오가 많았어서 처음 접근했던 방법이 잘 기억이 안 난다. (시작부터 하나하나 적어버릇 하는게 좋겠다.)
‘막힌 길이네. 다른 곳으로 이동하자’ 같은 느낌으로, 오답을 낼 때마다 그 부분을 메우는 식이었다. 주먹구구식 여기여기 기운 듯한 로직으로, 코드가 지저분해서 접근 방법을 설명하기도 장황하다.
코드에서 하나하나 기운 부분을 보면서 살펴본다.
2. 제출한 답
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def is_long_pressed_name(name: str, typed: str) -> bool:
if name == typed: ## 동일한 문자열일 경우, True를 리턴하도록 해야하더라.
return True
if len(name) < len(typed): ## '길게 눌린 게 있으면 typed가 더 길 것이다'
gen_cur_name_char = generator_for_getting_name_char(name) ## 제너레이터를 써봤는데, 사실 이것 때문에 로직이 더 지저분해짐
cur_name_char = next(gen_cur_name_char)
pre_same_char: str = '' ## typed 중간에 불필요한 문자가 나올 수도 있다. 이전에 값이 같았는지도 확인해줘야해서 변수 만들어줌
for cur_typed_index, cur_typed_char in enumerate(typed):
if cur_name_char == cur_typed_char:
pre_same_char = cur_name_char
try:
cur_name_char = next(gen_cur_name_char) ## 값이 같았을 때 제너레이터에서 값을 꺼내오는데
except StopIteration: ## 제너레이터에서 값을 못 꺼내면 예외발생한다길래 예외 처리터 생성
for last in typed[cur_typed_index:]: #name은 다 썼겠다, typed의 나머지 부분이 동일한 문자열로 마무리 되었는지 확인
if last != cur_name_char:
return False
return True
else:
if cur_typed_char != pre_same_char: ## typed의 현 인덱스 문자와 이전 문자가 다르면 중간에 불필요한 문자가 나온 케이스다
return False
return False
def generator_for_getting_name_char(name: str):
for cur_name_char in name:
yield cur_name_char
시간 복잡도는 O(n) 이다. 알고보니, 바로 개선할 수 있는 부분도 보인다. (첫 번째줄의 name과 typed의 비교다. 4. 문자열 리터럴 비교와 변수에 저장된 문자열의 비교 참고.)
지금은 시간복잡도를 줄이는 것에 대해 고려하는 것보다도, 코드 자체에 대한 되새김이 필요하다고 생각한다. 읽기도 불편하고 로직의 흐름이 중구난방이다. 왜 이런 코드가 탄생했을지에 대해 생각해본다.
3. 코드에 대한 반성
3.1 코드가 왜 누더기 같아 보일까?
코드 길이에 비해 변수가 많고, 변수명들이 한 눈에 딱 들어오지 않는다
변수가 많은 이유
구조적인 생각에서 만들어진 변수가 아니라 로직을 진행하면서 그때그때 필요한 것을 추가해서로 보인다.
변수명들이 한 눈에 딱 들어오지 않는 이유 일단 변수의 시작 부분부터가 아쉽다. 해당 변수의 정체성이 딱 느껴지기보다 다른 변수들과 중복된다. (ex. cur) 이는 곧, cur 이후까지 더 읽어야 변수가 뭐하는 녀석인지 파악할 수 있다는 말이기도 하다.
비슷하게, 공통적인 문자열을 포함한 경우가 많다 (ex. cur, char) 이는 매 변수를 볼 때마다 유의깊게 봐야지 변수가 분간이 된다는 얘기다.
추상적이기도 하다. (ex. last)
굳이 제너레이터를 써서 코드가 보기 쉽지 않다
왜 제너레이터를 썼지?
우스운 이유긴 하지만, 어제 제너레이터를 알게 돼서인 것 같다. 이걸 꼭 써봐야지! 라기보단, 마치 후입선출이라도 되는 것처럼 따끈하게 알게된 걸 우선적인 재료로 꺼내온 것으로 보인다. 이는 좀 더 파이썬에 대해 좀 더 알게 되고, 많이 다뤄 보면 개선될 사항으로 보이긴 한다.
일단 멈춰서서 꼭 이 방법으로 해야할까? 더 단순하게 할 순 없을까? 를 생각할 수 있는 습관을 들이면 더욱 좋을 것이다. 이건, 훈련이 필요할 것이다.
여기저기서 조건에 따라 그때그때 리턴을 해서 로직의 흐름이 한 눈에 들어오지 않는다
이건 변수가 많아진 이유처럼, 구조적인 생각에서 만들어진 것이 아니라, 그때그때 기워서 그렇다.
3.2 왜 누더기가 되었을까?
포괄하자면, 이유는 확실하다.
생겨날 수 있는 예외적인 케이스들에 대해 생각하지 못했다.
그래서 처음부터 구멍이 난 로직으로 시작을 한 다음에, 틀리는 케이스에 맞게 여기저기 기우는 방향으로 가기 시작했던 것 같다.
그리고 이를 포괄하는 로직으로 정돈하지 못했다.
코드가 지저분하다는 것은, 내 머릿속을 정리하지 못한 것의 영향이 크다고 생각한다. 머릿속이 정리가 되어 있지 않으면 코드를 깔끔하게 짤 수가 없다.
그런 면에서 코드를 쓰는 건 글쓰기와 닮은 면이 있다. 생각을 표현했다는 면에 있어서. 난 코드가 글쓰기보다 퇴고가 어렵다고 느낀다.
왜 더 까다롭지?
잘 못 쓴 코드가 잘 못 쓴 글쓰기보다 더 전후 인과적인 관계성이 강하다고 생각한다. 그때그때 뱉어내면서 인과 관계를 모두 이어버리고 역할을 통으로 묶은 코드는 딱딱해서 변경하기가 어렵다. 최악의 경우에는 다 엎어야 될 수도 있다.
또 코드는 보다 ‘목적성’이 뚜렷해야한다고 생각한다. 애초에 X에 대한 수단이기 때문이다. ‘코드를 작성한다’는 단편적인 행위에 초점을 맞춰서 보자면 목적이 아주 명확하다.
‘기능대로 동작하는 프로그램을 만든다’
왜 프로그램을 만드는가, 는 인문학적으로도 나아갈 수 있는 광범위한 생각이 될 수 있을 것이다.
여튼 간단하게 매듭을 한번 짓자면 여기서 덧붙는 것들은,
유한한 자원을 사용해서, 효율적이고 안정적으로, 다른 사람들도 읽고 수정하기 쉽게
가 되겠다. 기능대로 동작하기만 하는 거면 내가 오랜 시간에 걸쳐 기워 만든 저 누더기 동무도 훌륭할텐데, 아쉽게도 그렇지가 않다. 프로그램은 유한한 자원을 사용하며, 대개의 경우 여러 사람들에 의해 개발 및 유지보수되며, 변경 되는게 당연한 처지다.
물론 이 문제를 누더기로 푼건 아무 문제가 되지 않고, 앞으로도 난 원하지 않아도 누더기 코드를 짜곤 할테지만 지속적으로 의식하는 것이 중요하다고 생각한다.
컴퓨터에게도 인간에게도 쉬운 코드를 짜도록 연습하자.
오늘의 문제를 두고 봤을 땐, 좀 더 계획적이고 정돈된 로직을 마련해 그것을 전개하는 것이 필요할텐데 사실 이건 연습이 많이 필요할 것 같다. 우선은 침착하게 조건과 요구사항을 확인한 뒤에, 생각을 적어보고 누더기를 차근차근 짜봐야겠다.
4. 문자열 리터럴 비교와 변수에 저장된 문자열의 비교
파이썬은 종종 같은 리터럴 문자열을 메모리의 같은 위치에 저장하는 최적화를 수행한다고 한다.(문자열 인터닝) 그래서, 그렇게 인터닝 된 문자열의 경우 if “abc” == “abc” 같은 리터럴 비교시 실제 동일한 메모리 주소를 비교할 수 있어 O(1)의 시간복잡도로 실행될 수 있다.
하지만 변수에 저장된 문자열인 경우, 파이썬은 런타임에 두 문자열의 값을 비교해야한다. 그래서 두 문자열의 길이 비교, 길이가 같다면 각 문자를 순차적으로 비교하는 과정을 거치므로 O(n)의 시간이 소모되게 된다. 두 문자열이 완전히 같다면 끝까지 다 확인해야하는 거고.
5. 문자열 인터닝(String Interning)
소스 코드에 직접 작성된 문자열 리터널은 종종 인터닝 된다고 한다. 또한 intern() 함수를 사용하면 명시적으로 문자열을 인터닝할 수 있다. 런타임에 문자열을 합치거나 수정하여 생성된 문자열은 자동으로 인터닝되지 않는다고 한다. (ex. 사용자 입력이나 파일에서 읽은 데이터, 문자열의 join(), format(), 슬라이싱 등을 통해 생성된 문자열)
기본적으로 파이썬 인터프리터는 성능 최적화를 위해 선택적으로 인터닝을 수행한다고 하고, 모든 문자열을 인터닝하는 것은 성능에 부정적인 영향을 미칠 수 있으니 문자열 처리 방식은 좀 더 신중한 것이 좋을 것이다. ㄴ
6. 더 나은 코드
chatGPT에게 물어본 코드. 훨씬 깔끔하고 간결하다. 하지만 이보다 더 직관적으로 로직이 눈에 들어올만한 코드를 짤 수 있지 않을까? 추후 좀 레벨업하고 나면 다시 접근해봐야겠다.
1
2
3
4
5
6
7
8
9
10
11
12
class Solution:
def isLongPressedName(self, name: str, typed: str) -> bool:
name_index, typed_index = 0, 0
while typed_index < len(typed):
if name_index < len(name) and name[name_index] == typed[typed_index]:
name_index += 1
elif typed_index == 0 or typed[typed_index] != typed[typed_index - 1]:
return False
typed_index += 1
return name_index == len(name)
7. 추가 공부
더 나은 코드. 실력이 좀 늘면 다시 풀어보자.